Crop background from Image
$begingroup$
I try to write a program to crop background from an image.
This is a sample of my training data.
I have images with and without a background. (manually cropped)
The background is always similar (changes of light and so on. Sometimes people on random places.)
The object is always on the same place but not always the same (there are different models).
Can someone give me an advice how I can solve this Problem?
What is the right way to do something like this???


deep-learning image-classification image-recognition
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
$endgroup$
add a comment |
$begingroup$
I try to write a program to crop background from an image.
This is a sample of my training data.
I have images with and without a background. (manually cropped)
The background is always similar (changes of light and so on. Sometimes people on random places.)
The object is always on the same place but not always the same (there are different models).
Can someone give me an advice how I can solve this Problem?
What is the right way to do something like this???
deep-learning image-classification image-recognition
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
$endgroup$
1
$begingroup$
What is the size of your dataset?
$endgroup$
– Armen Aghajanyan
Dec 5 '16 at 7:55
$begingroup$
about 2000 images
$endgroup$
– Dawid Cz
Dec 5 '16 at 7:57
1
$begingroup$
Usually, people use a background subtraction technique. The most basic technique is to compute the average frame and then compare against each frame. But there are much more sophisticated techniques. Packages like opencv come with lots of background subtraction implementations.
$endgroup$
– Ricardo Cruz
Dec 8 '16 at 22:30
$begingroup$
That´s what I need. Thx I`ll check it.
$endgroup$
– Dawid Cz
Dec 9 '16 at 7:48
$begingroup$
I have found here something like this stackoverflow.com/questions/17884526/…
$endgroup$
– Dawid Cz
Dec 10 '16 at 12:00
add a comment |
$begingroup$
I try to write a program to crop background from an image.
This is a sample of my training data.
I have images with and without a background. (manually cropped)
The background is always similar (changes of light and so on. Sometimes people on random places.)
The object is always on the same place but not always the same (there are different models).
Can someone give me an advice how I can solve this Problem?
What is the right way to do something like this???
deep-learning image-classification image-recognition
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
$endgroup$
I try to write a program to crop background from an image.
This is a sample of my training data.
I have images with and without a background. (manually cropped)
The background is always similar (changes of light and so on. Sometimes people on random places.)
The object is always on the same place but not always the same (there are different models).
Can someone give me an advice how I can solve this Problem?
What is the right way to do something like this???
deep-learning image-classification image-recognition
deep-learning image-classification image-recognition
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
edited Aug 30 '17 at 23:02
Stephen Rauch
1,52551330
1,52551330
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
asked Dec 4 '16 at 18:24
Dawid CzDawid Cz
2314
2314
1
$begingroup$
What is the size of your dataset?
$endgroup$
– Armen Aghajanyan
Dec 5 '16 at 7:55
$begingroup$
about 2000 images
$endgroup$
– Dawid Cz
Dec 5 '16 at 7:57
1
$begingroup$
Usually, people use a background subtraction technique. The most basic technique is to compute the average frame and then compare against each frame. But there are much more sophisticated techniques. Packages like opencv come with lots of background subtraction implementations.
$endgroup$
– Ricardo Cruz
Dec 8 '16 at 22:30
$begingroup$
That´s what I need. Thx I`ll check it.
$endgroup$
– Dawid Cz
Dec 9 '16 at 7:48
$begingroup$
I have found here something like this stackoverflow.com/questions/17884526/…
$endgroup$
– Dawid Cz
Dec 10 '16 at 12:00
add a comment |
1
$begingroup$
What is the size of your dataset?
$endgroup$
– Armen Aghajanyan
Dec 5 '16 at 7:55
$begingroup$
about 2000 images
$endgroup$
– Dawid Cz
Dec 5 '16 at 7:57
1
$begingroup$
Usually, people use a background subtraction technique. The most basic technique is to compute the average frame and then compare against each frame. But there are much more sophisticated techniques. Packages like opencv come with lots of background subtraction implementations.
$endgroup$
– Ricardo Cruz
Dec 8 '16 at 22:30
$begingroup$
That´s what I need. Thx I`ll check it.
$endgroup$
– Dawid Cz
Dec 9 '16 at 7:48
$begingroup$
I have found here something like this stackoverflow.com/questions/17884526/…
$endgroup$
– Dawid Cz
Dec 10 '16 at 12:00
1
1
$begingroup$
What is the size of your dataset?
$endgroup$
– Armen Aghajanyan
Dec 5 '16 at 7:55
$begingroup$
What is the size of your dataset?
$endgroup$
– Armen Aghajanyan
Dec 5 '16 at 7:55
$begingroup$
about 2000 images
$endgroup$
– Dawid Cz
Dec 5 '16 at 7:57
$begingroup$
about 2000 images
$endgroup$
– Dawid Cz
Dec 5 '16 at 7:57
1
1
$begingroup$
Usually, people use a background subtraction technique. The most basic technique is to compute the average frame and then compare against each frame. But there are much more sophisticated techniques. Packages like opencv come with lots of background subtraction implementations.
$endgroup$
– Ricardo Cruz
Dec 8 '16 at 22:30
$begingroup$
Usually, people use a background subtraction technique. The most basic technique is to compute the average frame and then compare against each frame. But there are much more sophisticated techniques. Packages like opencv come with lots of background subtraction implementations.
$endgroup$
– Ricardo Cruz
Dec 8 '16 at 22:30
$begingroup$
That´s what I need. Thx I`ll check it.
$endgroup$
– Dawid Cz
Dec 9 '16 at 7:48
$begingroup$
That´s what I need. Thx I`ll check it.
$endgroup$
– Dawid Cz
Dec 9 '16 at 7:48
$begingroup$
I have found here something like this stackoverflow.com/questions/17884526/…
$endgroup$
– Dawid Cz
Dec 10 '16 at 12:00
$begingroup$
I have found here something like this stackoverflow.com/questions/17884526/…
$endgroup$
– Dawid Cz
Dec 10 '16 at 12:00
add a comment |
3 Answers
3
active
oldest
votes
$begingroup$
This is indeed a simple problem if tried to be tackled using semantic segmentation. Semantic segmentation itself is a computer vision problem that could be understood as an extension of object detection and could be understood as follows:
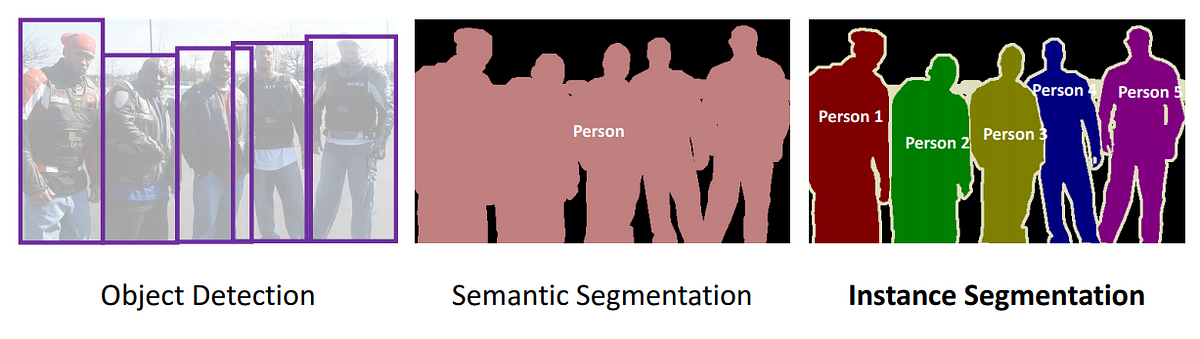
Using semantic segmentation done using a network called as UNET, the model could be trained for the required image and then it can be extended to find the boundary of the required object and finally extract it. UNET architecture could be understood using the following diagram:

UNET's are generally used to create mask that could be XOR with the actual image and the background of the image could be subtracted easily.
Completely explaining image segmentation using UNET or any other technique falls beyond the limit of the answer and thus a better explanation could be found in this article
If you want the practical implementation/codes of the same, they could be found here on kaggle kernels of the following contests:
- TGS Salt Identification Challenge
- Carvana Image Masking Challenge
answered 7 hours ago
thanatozthanatoz
569319
$endgroup$
add a comment |
$begingroup$
The task you are trying to perform is called semantic segmentation (or pixel-wise segmentation). There exists extensive literature on the subject and numerous tutorials/online resources to get you started, such as this one
Fully convolutional networks (FCN) popularized the core components of state-of-the-art semantic segmentation techniques. They have since evolved into numerous superior, yet related, networks, many of which are covered in the link above.
Although the linked website is quite comprehensive, it does not mention mask rcnn, which has performed very well and at relatively fast speeds (~5 fps). It is definitely worth exploring!
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
$endgroup$
add a comment |
$begingroup$
You can use fully convolutional neural nets for image segmentation. Check out the kernels in the kaggle competition: Carvana Image Masking Challenge
.
Also check out Fully Convolutional Neural Network
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
$endgroup$
add a comment |
Your Answer
StackExchange.ifUsing("editor", function () {
return StackExchange.using("mathjaxEditing", function () {
StackExchange.MarkdownEditor.creationCallbacks.add(function (editor, postfix) {
StackExchange.mathjaxEditing.prepareWmdForMathJax(editor, postfix, [["$", "$"], ["\\(","\\)"]]);
});
});
}, "mathjax-editing");
StackExchange.ready(function() {
var channelOptions = {
tags: "".split(" "),
id: "557"
};
initTagRenderer("".split(" "), "".split(" "), channelOptions);
StackExchange.using("externalEditor", function() {
// Have to fire editor after snippets, if snippets enabled
if (StackExchange.settings.snippets.snippetsEnabled) {
StackExchange.using("snippets", function() {
createEditor();
});
}
else {
createEditor();
}
});
function createEditor() {
StackExchange.prepareEditor({
heartbeatType: 'answer',
autoActivateHeartbeat: false,
convertImagesToLinks: false,
noModals: true,
showLowRepImageUploadWarning: true,
reputationToPostImages: null,
bindNavPrevention: true,
postfix: "",
imageUploader: {
brandingHtml: "Powered by u003ca class="icon-imgur-white" href="https://imgur.com/"u003eu003c/au003e",
contentPolicyHtml: "User contributions licensed under u003ca href="https://creativecommons.org/licenses/by-sa/3.0/"u003ecc by-sa 3.0 with attribution requiredu003c/au003e u003ca href="https://stackoverflow.com/legal/content-policy"u003e(content policy)u003c/au003e",
allowUrls: true
},
onDemand: true,
discardSelector: ".discard-answer"
,immediatelyShowMarkdownHelp:true
});
}
});
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
StackExchange.ready(
function () {
StackExchange.openid.initPostLogin('.new-post-login', 'https%3a%2f%2fdatascience.stackexchange.com%2fquestions%2f15509%2fcrop-background-from-image%23new-answer', 'question_page');
}
);
Post as a guest
Required, but never shown
3 Answers
3
active
oldest
votes
3 Answers
3
active
oldest
votes
active
oldest
votes
active
oldest
votes
$begingroup$
This is indeed a simple problem if tried to be tackled using semantic segmentation. Semantic segmentation itself is a computer vision problem that could be understood as an extension of object detection and could be understood as follows:
Using semantic segmentation done using a network called as UNET, the model could be trained for the required image and then it can be extended to find the boundary of the required object and finally extract it. UNET architecture could be understood using the following diagram:
UNET's are generally used to create mask that could be XOR with the actual image and the background of the image could be subtracted easily.
Completely explaining image segmentation using UNET or any other technique falls beyond the limit of the answer and thus a better explanation could be found in this article
If you want the practical implementation/codes of the same, they could be found here on kaggle kernels of the following contests:
- TGS Salt Identification Challenge
- Carvana Image Masking Challenge
answered 7 hours ago
thanatozthanatoz
569319
$endgroup$
add a comment |
$begingroup$
This is indeed a simple problem if tried to be tackled using semantic segmentation. Semantic segmentation itself is a computer vision problem that could be understood as an extension of object detection and could be understood as follows:
Using semantic segmentation done using a network called as UNET, the model could be trained for the required image and then it can be extended to find the boundary of the required object and finally extract it. UNET architecture could be understood using the following diagram:
UNET's are generally used to create mask that could be XOR with the actual image and the background of the image could be subtracted easily.
Completely explaining image segmentation using UNET or any other technique falls beyond the limit of the answer and thus a better explanation could be found in this article
If you want the practical implementation/codes of the same, they could be found here on kaggle kernels of the following contests:
- TGS Salt Identification Challenge
- Carvana Image Masking Challenge
answered 7 hours ago
thanatozthanatoz
569319
$endgroup$
add a comment |
$begingroup$
This is indeed a simple problem if tried to be tackled using semantic segmentation. Semantic segmentation itself is a computer vision problem that could be understood as an extension of object detection and could be understood as follows:
Using semantic segmentation done using a network called as UNET, the model could be trained for the required image and then it can be extended to find the boundary of the required object and finally extract it. UNET architecture could be understood using the following diagram:
UNET's are generally used to create mask that could be XOR with the actual image and the background of the image could be subtracted easily.
Completely explaining image segmentation using UNET or any other technique falls beyond the limit of the answer and thus a better explanation could be found in this article
If you want the practical implementation/codes of the same, they could be found here on kaggle kernels of the following contests:
- TGS Salt Identification Challenge
- Carvana Image Masking Challenge
answered 7 hours ago
thanatozthanatoz
569319
$endgroup$
This is indeed a simple problem if tried to be tackled using semantic segmentation. Semantic segmentation itself is a computer vision problem that could be understood as an extension of object detection and could be understood as follows:
Using semantic segmentation done using a network called as UNET, the model could be trained for the required image and then it can be extended to find the boundary of the required object and finally extract it. UNET architecture could be understood using the following diagram:
UNET's are generally used to create mask that could be XOR with the actual image and the background of the image could be subtracted easily.
Completely explaining image segmentation using UNET or any other technique falls beyond the limit of the answer and thus a better explanation could be found in this article
If you want the practical implementation/codes of the same, they could be found here on kaggle kernels of the following contests:
- TGS Salt Identification Challenge
- Carvana Image Masking Challenge
answered 7 hours ago
thanatozthanatoz
569319
answered 7 hours ago
thanatozthanatoz
569319
answered 7 hours ago
thanatozthanatoz
569319
answered 7 hours ago
thanatozthanatoz
569319
569319
add a comment |
add a comment |
$begingroup$
The task you are trying to perform is called semantic segmentation (or pixel-wise segmentation). There exists extensive literature on the subject and numerous tutorials/online resources to get you started, such as this one
Fully convolutional networks (FCN) popularized the core components of state-of-the-art semantic segmentation techniques. They have since evolved into numerous superior, yet related, networks, many of which are covered in the link above.
Although the linked website is quite comprehensive, it does not mention mask rcnn, which has performed very well and at relatively fast speeds (~5 fps). It is definitely worth exploring!
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
$endgroup$
add a comment |
$begingroup$
The task you are trying to perform is called semantic segmentation (or pixel-wise segmentation). There exists extensive literature on the subject and numerous tutorials/online resources to get you started, such as this one
Fully convolutional networks (FCN) popularized the core components of state-of-the-art semantic segmentation techniques. They have since evolved into numerous superior, yet related, networks, many of which are covered in the link above.
Although the linked website is quite comprehensive, it does not mention mask rcnn, which has performed very well and at relatively fast speeds (~5 fps). It is definitely worth exploring!
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
$endgroup$
add a comment |
$begingroup$
The task you are trying to perform is called semantic segmentation (or pixel-wise segmentation). There exists extensive literature on the subject and numerous tutorials/online resources to get you started, such as this one
Fully convolutional networks (FCN) popularized the core components of state-of-the-art semantic segmentation techniques. They have since evolved into numerous superior, yet related, networks, many of which are covered in the link above.
Although the linked website is quite comprehensive, it does not mention mask rcnn, which has performed very well and at relatively fast speeds (~5 fps). It is definitely worth exploring!
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
$endgroup$
The task you are trying to perform is called semantic segmentation (or pixel-wise segmentation). There exists extensive literature on the subject and numerous tutorials/online resources to get you started, such as this one
Fully convolutional networks (FCN) popularized the core components of state-of-the-art semantic segmentation techniques. They have since evolved into numerous superior, yet related, networks, many of which are covered in the link above.
Although the linked website is quite comprehensive, it does not mention mask rcnn, which has performed very well and at relatively fast speeds (~5 fps). It is definitely worth exploring!
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
answered Apr 20 '18 at 4:24
Benji AlbertBenji Albert
836314
836314
add a comment |
add a comment |
$begingroup$
You can use fully convolutional neural nets for image segmentation. Check out the kernels in the kaggle competition: Carvana Image Masking Challenge
.
Also check out Fully Convolutional Neural Network
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
$endgroup$
add a comment |
$begingroup$
You can use fully convolutional neural nets for image segmentation. Check out the kernels in the kaggle competition: Carvana Image Masking Challenge
.
Also check out Fully Convolutional Neural Network
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
$endgroup$
add a comment |
$begingroup$
You can use fully convolutional neural nets for image segmentation. Check out the kernels in the kaggle competition: Carvana Image Masking Challenge
.
Also check out Fully Convolutional Neural Network
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
$endgroup$
You can use fully convolutional neural nets for image segmentation. Check out the kernels in the kaggle competition: Carvana Image Masking Challenge
.
Also check out Fully Convolutional Neural Network
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
edited Dec 29 '17 at 2:54
Stephen Rauch
1,52551330
1,52551330
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
answered Aug 30 '17 at 22:08
Rahul ChandnaniRahul Chandnani
1
1
add a comment |
add a comment |
Thanks for contributing an answer to Data Science Stack Exchange!
- Please be sure to answer the question. Provide details and share your research!
But avoid …
- Asking for help, clarification, or responding to other answers.
- Making statements based on opinion; back them up with references or personal experience.
Use MathJax to format equations. MathJax reference.
To learn more, see our tips on writing great answers.
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
StackExchange.ready(
function () {
StackExchange.openid.initPostLogin('.new-post-login', 'https%3a%2f%2fdatascience.stackexchange.com%2fquestions%2f15509%2fcrop-background-from-image%23new-answer', 'question_page');
}
);
Post as a guest
Required, but never shown
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown



1
$begingroup$
What is the size of your dataset?
$endgroup$
– Armen Aghajanyan
Dec 5 '16 at 7:55
$begingroup$
about 2000 images
$endgroup$
– Dawid Cz
Dec 5 '16 at 7:57
1
$begingroup$
Usually, people use a background subtraction technique. The most basic technique is to compute the average frame and then compare against each frame. But there are much more sophisticated techniques. Packages like opencv come with lots of background subtraction implementations.
$endgroup$
– Ricardo Cruz
Dec 8 '16 at 22:30
$begingroup$
That´s what I need. Thx I`ll check it.
$endgroup$
– Dawid Cz
Dec 9 '16 at 7:48
$begingroup$
I have found here something like this stackoverflow.com/questions/17884526/…
$endgroup$
– Dawid Cz
Dec 10 '16 at 12:00