Suilla
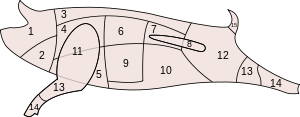
Suillae disiunctionis schema.
Suilla sive porcina porci caro est. In varias edibiles partes suilla dividitur. In Europa et in Asia Orientali crebro manducatissima caro est. In Germania anno 2004 consumptio pro capite 39,5 kg(39,3 kg anno 2003/tota carnica consumptio 61,3 kg) fuit. Contra, in aliquibus religionibus (velut Islamismo et Iudaismo) suilla omnino vetitur.
Porci in praesenti circiter 180 dies nati et cum pondere inter 95 et 110 kg immolantur.
Civitates productoriae |
Maxima suillae productoria natio Sina est quam Civitates Foederatae et Germania sequuntur. Aliae ponderis Europaeae productoriae nationes Hispania, Francia, Polonia et Dania est.
| Ordo | Natio | Productio (milibus tonnarum) | Ordo | Natio | Productio (milibus tonnarum) |
|---|---|---|---|---|---|
| 1 | Sina | 47 753 | 10 | Russia | 1 750 |
| 2 | Civitates Foederatae | 9 332 | 11 | Vietnamia | 1 700 |
| 3 | Germania | 4 366 | 12 | Italia | 1 618 |
| 4 | Hispania | 3 335 | 13 | Philippinae | 1 400 |
| 5 | Brasilia | 3 110 | |||
| 6 | Francia | 2 290 | 15 | Nederlandia | 1 245 |
| 7 | Polonia | 2 100 | 16 | Respublica Coreana | 1 100 |
| 8 | Canada | 1 970 | 17 | Mexicum | 1 100 |
| 9 | Dania | 1 762 | 18 | Belgia | 1 050 |
Fons: Handelsblatt – Die Welt in Zahlen (2005)
Nexus interni
- Collegium Porcinae Nationale
- Poc chuc


