Interrete
Media socialia
- Blogosphaera
- Snail mail
- Locutorium
- Forum
- ICANN
- .com
- Protocollum interretiale
- Hypertextus
- Memex
- Interpretes JavaScript
- Memex
- Nexus
- Podcast
- Automaton communicativum
- Tela totius terrae
- Permutatio fasciculorum
- Ethernet
- Navigatrum
- Whois
- Interretiarius
- IPv6
- Fascia lata
Censura interretialis
- Circumventio
- Expiscatio
- Malware
- Saginatio
Interrete[1] (prima littera maiuscula; -is, n)[1] aut rete informaticum[1] (-is, n)[1] (Anglice: Internet) est computatrorum maximorum rete quod plurima alia retia connectit. Data trans interrete, "fasciculis permutandis" (Anglice: packet switching), moventur, ut qualibet via a fonte ad ultimam metam iter faciant. Tela totius terrae, qua paginae hypertextuales communicantur, hoc interrete utitur.
Nationes plures et varias leges de interrete habent.
Nonnulla periodica Latina in Interreti eduntur.
Interretis fundamentum Protocollum Interretiale est.
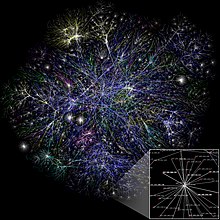
Imago viarum per partem interretis, quae data—notas, picturas, litteras electronicas, etc.—ferunt. Ex Opte Project.

Thermopolium interretiale.
Index
1 Historia
2 Proverbium
3 Notae
4 Nexus interni
5 Nexus externi
Historia |
Civitates Foederatae Americae Advanced Research Projects Agency anno 1958 creavit.
Proverbium |
"Quod non est in Interreti non est in mundo."[2]
"Verba volant, scripta manent (in Interreti)".
Notae |
↑ 1.01.11.21.3 Ebbe Vilborg, Norstedts svensk-latinska ordbok, editio secunda, 2009.
↑ Vide etiam "Quod non est in actis non est in mundo."
Nexus interni
- .com
- Censura interretialis
- Cybersecuritas
- Discrimen digitale
- Ethernet
- Expiscatio
- Forum interretiale
- ICANN
- IETF
- Malware
- Navigatrum
- Protocollum
- Protocollum Securitatis
- Second Life
- Situs interretialis
- Tela totius terrae
- Whois
Nexus externi |
Vicimedia Communia plura habent quae ad Interrete spectant. |
http://www.cern.ch/ .mw-parser-output .existinglinksgray a,.mw-parser-output .existinglinksgray a:visited{color:gray}.mw-parser-output .existinglinksgray a.new{color:#ba0000}.mw-parser-output .existinglinksgray a.new:visited{color:#a55858}
(Anglice, Francogallice)
Ars ingeniaria · Agricultura · Computatra · Electronica · Informatica · Interrete · Vehicula


