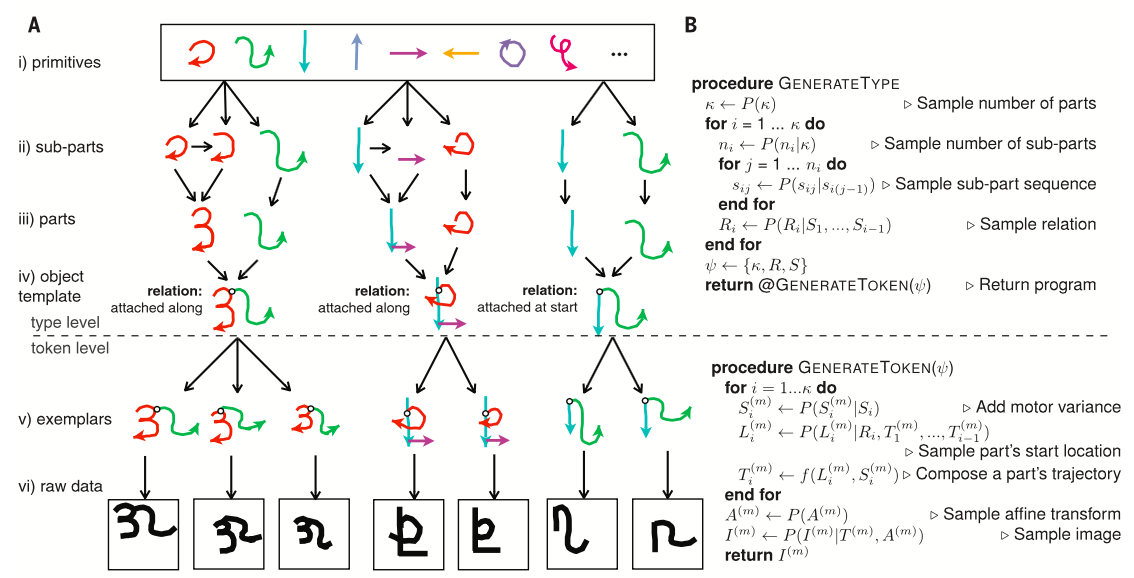
What methods can be used to detect duplicacy in image dataset?
$begingroup$
I want to remove duplicate images from a dataset of 50Million images. What is the best method to detect all the duplicates?
Do you think one shot learning is good for this?
deep-learning predictive-modeling data-cleaning image-classification ensemble-modeling
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
$endgroup$
add a comment |
$begingroup$
I want to remove duplicate images from a dataset of 50Million images. What is the best method to detect all the duplicates?
Do you think one shot learning is good for this?
deep-learning predictive-modeling data-cleaning image-classification ensemble-modeling
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
$endgroup$
$begingroup$
Exact duplicates?
$endgroup$
– Michael M
Sep 28 '18 at 19:16
$begingroup$
No, even augmented ones.
$endgroup$
– thanatoz
Sep 28 '18 at 19:17
add a comment |
$begingroup$
I want to remove duplicate images from a dataset of 50Million images. What is the best method to detect all the duplicates?
Do you think one shot learning is good for this?
deep-learning predictive-modeling data-cleaning image-classification ensemble-modeling
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
$endgroup$
I want to remove duplicate images from a dataset of 50Million images. What is the best method to detect all the duplicates?
Do you think one shot learning is good for this?
deep-learning predictive-modeling data-cleaning image-classification ensemble-modeling
deep-learning predictive-modeling data-cleaning image-classification ensemble-modeling
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
edited Sep 30 '18 at 14:07
thanatoz
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
asked Sep 28 '18 at 19:09
thanatozthanatoz
504317
504317
$begingroup$
Exact duplicates?
$endgroup$
– Michael M
Sep 28 '18 at 19:16
$begingroup$
No, even augmented ones.
$endgroup$
– thanatoz
Sep 28 '18 at 19:17
add a comment |
$begingroup$
Exact duplicates?
$endgroup$
– Michael M
Sep 28 '18 at 19:16
$begingroup$
No, even augmented ones.
$endgroup$
– thanatoz
Sep 28 '18 at 19:17
$begingroup$
Exact duplicates?
$endgroup$
– Michael M
Sep 28 '18 at 19:16
$begingroup$
Exact duplicates?
$endgroup$
– Michael M
Sep 28 '18 at 19:16
$begingroup$
No, even augmented ones.
$endgroup$
– thanatoz
Sep 28 '18 at 19:17
$begingroup$
No, even augmented ones.
$endgroup$
– thanatoz
Sep 28 '18 at 19:17
add a comment |
2 Answers
2
active
oldest
votes
$begingroup$
I think the dhash technique might help. It essentially creates a signature for each image, then you could isolate the duplicated images. 50M could take a while, so perhaps you can try that with a smaller subset and see how well it works.
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
$endgroup$
$begingroup$
Is there a descriptive guide to use this apart from the official jetsetter page?
$endgroup$
– thanatoz
Oct 1 '18 at 7:22
$begingroup$
Are you looking for implementation example in a certain language? If you look through the jetsetter article and its references, you can see code sample implementation in C#, PHP, etc. Many people are kind enough to share the code via github as well and hopefully one of them would work for you.
$endgroup$
– The Lyrist
Oct 1 '18 at 18:29
add a comment |
$begingroup$
So, this is a simple problem that could be solved using one-shot learning technique. To achieve this, we must build a model that understands our data and is capable of finding similarity or dissimilarity in your data.
For this, we must carry out the following steps:
- Train (or finetune) the network on dataset of related images.
- After training the model, clip the last predicting layers to create embedding.
- Pass your testing data through the network and store individual embedding.
- Find the difference between the embedding and find the differences crossing a certain threshold.
- These images are potentially images having similar data and this could be easily used to find duplicacy in the dataset.
I referred this paper on oneshot learning and later found this blog to be a little helpful.
answered 27 mins ago
thanatozthanatoz
504317
$endgroup$
add a comment |

StackExchange.ifUsing("editor", function () {
return StackExchange.using("mathjaxEditing", function () {
StackExchange.MarkdownEditor.creationCallbacks.add(function (editor, postfix) {
StackExchange.mathjaxEditing.prepareWmdForMathJax(editor, postfix, [["$", "$"], ["\\(","\\)"]]);
});
});
}, "mathjax-editing");
StackExchange.ready(function() {
var channelOptions = {
tags: "".split(" "),
id: "557"
};
initTagRenderer("".split(" "), "".split(" "), channelOptions);
StackExchange.using("externalEditor", function() {
// Have to fire editor after snippets, if snippets enabled
if (StackExchange.settings.snippets.snippetsEnabled) {
StackExchange.using("snippets", function() {
createEditor();
});
}
else {
createEditor();
}
});
function createEditor() {
StackExchange.prepareEditor({
heartbeatType: 'answer',
autoActivateHeartbeat: false,
convertImagesToLinks: false,
noModals: true,
showLowRepImageUploadWarning: true,
reputationToPostImages: null,
bindNavPrevention: true,
postfix: "",
imageUploader: {
brandingHtml: "Powered by u003ca class="icon-imgur-white" href="https://imgur.com/"u003eu003c/au003e",
contentPolicyHtml: "User contributions licensed under u003ca href="https://creativecommons.org/licenses/by-sa/3.0/"u003ecc by-sa 3.0 with attribution requiredu003c/au003e u003ca href="https://stackoverflow.com/legal/content-policy"u003e(content policy)u003c/au003e",
allowUrls: true
},
onDemand: true,
discardSelector: ".discard-answer"
,immediatelyShowMarkdownHelp:true
});
}
});
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
StackExchange.ready(
function () {
StackExchange.openid.initPostLogin('.new-post-login', 'https%3a%2f%2fdatascience.stackexchange.com%2fquestions%2f38924%2fwhat-methods-can-be-used-to-detect-duplicacy-in-image-dataset%23new-answer', 'question_page');
}
);
Post as a guest
Required, but never shown
2 Answers
2
active
oldest
votes
2 Answers
2
active
oldest
votes
active
oldest
votes
active
oldest
votes
$begingroup$
I think the dhash technique might help. It essentially creates a signature for each image, then you could isolate the duplicated images. 50M could take a while, so perhaps you can try that with a smaller subset and see how well it works.
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
$endgroup$
$begingroup$
Is there a descriptive guide to use this apart from the official jetsetter page?
$endgroup$
– thanatoz
Oct 1 '18 at 7:22
$begingroup$
Are you looking for implementation example in a certain language? If you look through the jetsetter article and its references, you can see code sample implementation in C#, PHP, etc. Many people are kind enough to share the code via github as well and hopefully one of them would work for you.
$endgroup$
– The Lyrist
Oct 1 '18 at 18:29
add a comment |
$begingroup$
I think the dhash technique might help. It essentially creates a signature for each image, then you could isolate the duplicated images. 50M could take a while, so perhaps you can try that with a smaller subset and see how well it works.
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
$endgroup$
$begingroup$
Is there a descriptive guide to use this apart from the official jetsetter page?
$endgroup$
– thanatoz
Oct 1 '18 at 7:22
$begingroup$
Are you looking for implementation example in a certain language? If you look through the jetsetter article and its references, you can see code sample implementation in C#, PHP, etc. Many people are kind enough to share the code via github as well and hopefully one of them would work for you.
$endgroup$
– The Lyrist
Oct 1 '18 at 18:29
add a comment |
$begingroup$
I think the dhash technique might help. It essentially creates a signature for each image, then you could isolate the duplicated images. 50M could take a while, so perhaps you can try that with a smaller subset and see how well it works.
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
$endgroup$
I think the dhash technique might help. It essentially creates a signature for each image, then you could isolate the duplicated images. 50M could take a while, so perhaps you can try that with a smaller subset and see how well it works.
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
answered Sep 28 '18 at 21:32
The LyristThe Lyrist
419113
419113
$begingroup$
Is there a descriptive guide to use this apart from the official jetsetter page?
$endgroup$
– thanatoz
Oct 1 '18 at 7:22
$begingroup$
Are you looking for implementation example in a certain language? If you look through the jetsetter article and its references, you can see code sample implementation in C#, PHP, etc. Many people are kind enough to share the code via github as well and hopefully one of them would work for you.
$endgroup$
– The Lyrist
Oct 1 '18 at 18:29
add a comment |
$begingroup$
Is there a descriptive guide to use this apart from the official jetsetter page?
$endgroup$
– thanatoz
Oct 1 '18 at 7:22
$begingroup$
Are you looking for implementation example in a certain language? If you look through the jetsetter article and its references, you can see code sample implementation in C#, PHP, etc. Many people are kind enough to share the code via github as well and hopefully one of them would work for you.
$endgroup$
– The Lyrist
Oct 1 '18 at 18:29
$begingroup$
Is there a descriptive guide to use this apart from the official jetsetter page?
$endgroup$
– thanatoz
Oct 1 '18 at 7:22
$begingroup$
Is there a descriptive guide to use this apart from the official jetsetter page?
$endgroup$
– thanatoz
Oct 1 '18 at 7:22
$begingroup$
Are you looking for implementation example in a certain language? If you look through the jetsetter article and its references, you can see code sample implementation in C#, PHP, etc. Many people are kind enough to share the code via github as well and hopefully one of them would work for you.
$endgroup$
– The Lyrist
Oct 1 '18 at 18:29
$begingroup$
Are you looking for implementation example in a certain language? If you look through the jetsetter article and its references, you can see code sample implementation in C#, PHP, etc. Many people are kind enough to share the code via github as well and hopefully one of them would work for you.
$endgroup$
– The Lyrist
Oct 1 '18 at 18:29
add a comment |
$begingroup$
So, this is a simple problem that could be solved using one-shot learning technique. To achieve this, we must build a model that understands our data and is capable of finding similarity or dissimilarity in your data.
For this, we must carry out the following steps:
- Train (or finetune) the network on dataset of related images.
- After training the model, clip the last predicting layers to create embedding.
- Pass your testing data through the network and store individual embedding.
- Find the difference between the embedding and find the differences crossing a certain threshold.
- These images are potentially images having similar data and this could be easily used to find duplicacy in the dataset.
I referred this paper on oneshot learning and later found this blog to be a little helpful.
answered 27 mins ago
thanatozthanatoz
504317
$endgroup$
add a comment |
$begingroup$
So, this is a simple problem that could be solved using one-shot learning technique. To achieve this, we must build a model that understands our data and is capable of finding similarity or dissimilarity in your data.
For this, we must carry out the following steps:
- Train (or finetune) the network on dataset of related images.
- After training the model, clip the last predicting layers to create embedding.
- Pass your testing data through the network and store individual embedding.
- Find the difference between the embedding and find the differences crossing a certain threshold.
- These images are potentially images having similar data and this could be easily used to find duplicacy in the dataset.
I referred this paper on oneshot learning and later found this blog to be a little helpful.
answered 27 mins ago
thanatozthanatoz
504317
$endgroup$
add a comment |
$begingroup$
So, this is a simple problem that could be solved using one-shot learning technique. To achieve this, we must build a model that understands our data and is capable of finding similarity or dissimilarity in your data.
For this, we must carry out the following steps:
- Train (or finetune) the network on dataset of related images.
- After training the model, clip the last predicting layers to create embedding.
- Pass your testing data through the network and store individual embedding.
- Find the difference between the embedding and find the differences crossing a certain threshold.
- These images are potentially images having similar data and this could be easily used to find duplicacy in the dataset.
I referred this paper on oneshot learning and later found this blog to be a little helpful.
answered 27 mins ago
thanatozthanatoz
504317
$endgroup$
So, this is a simple problem that could be solved using one-shot learning technique. To achieve this, we must build a model that understands our data and is capable of finding similarity or dissimilarity in your data.
For this, we must carry out the following steps:
- Train (or finetune) the network on dataset of related images.
- After training the model, clip the last predicting layers to create embedding.
- Pass your testing data through the network and store individual embedding.
- Find the difference between the embedding and find the differences crossing a certain threshold.
- These images are potentially images having similar data and this could be easily used to find duplicacy in the dataset.
I referred this paper on oneshot learning and later found this blog to be a little helpful.
answered 27 mins ago
thanatozthanatoz
504317
answered 27 mins ago
thanatozthanatoz
504317
answered 27 mins ago
thanatozthanatoz
504317
answered 27 mins ago
thanatozthanatoz
504317
504317
add a comment |
add a comment |
Thanks for contributing an answer to Data Science Stack Exchange!
- Please be sure to answer the question. Provide details and share your research!
But avoid …
- Asking for help, clarification, or responding to other answers.
- Making statements based on opinion; back them up with references or personal experience.
Use MathJax to format equations. MathJax reference.
To learn more, see our tips on writing great answers.
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
StackExchange.ready(
function () {
StackExchange.openid.initPostLogin('.new-post-login', 'https%3a%2f%2fdatascience.stackexchange.com%2fquestions%2f38924%2fwhat-methods-can-be-used-to-detect-duplicacy-in-image-dataset%23new-answer', 'question_page');
}
);
Post as a guest
Required, but never shown
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Sign up or log in
StackExchange.ready(function () {
StackExchange.helpers.onClickDraftSave('#login-link');
});
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown
Required, but never shown



$begingroup$
Exact duplicates?
$endgroup$
– Michael M
Sep 28 '18 at 19:16
$begingroup$
No, even augmented ones.
$endgroup$
– thanatoz
Sep 28 '18 at 19:17