Porta ET
| INDUCTA | EDUCTUM | |
| A | B | A ET B |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Porta ET seu porta AND (ex Anglica) est porta logica digitalis quae coniunctionem logicalem efficit. Gerit ut tabula veritatis quae ad dextram videre potest. Datum eductum est SUPERNUM (1) solum si uterque data inducta portae sunt SUPERNA. Si nullum aut solum unum datum inductum portae est SUPERNUM, data eductum est SUBMISSUM (0). In sensu alio, functio ET minimum duorum digitorum educit, sicut functio AUT maximum educit.
Index
1 Symbola
2 Aequatio Booleana
3 Forma
3.1 Forma alterna
4 Notae
5 Nexus interni
Symbola |
Sunt tria symbola pro portis ET: symbolum ANSI ("Americanum" aut "militare"), symbolum IEC ("Europaeum" aut "rectangulare") aut IEEE, et obsoletum symbolum DIN. Lex IEEE et symbola "formarum distinctarum" et "formarum rectangularum" pro portis logicis simplicis sinit. Si vis, vide etiam Symboli Portae Logicae.
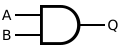
Symbolum MIL/ANSI [1]

Symbolum IEC/IEEE [2]
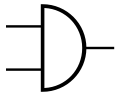
Symbolum DIN



Aequatio Booleana |
Porta ET cum inducta A et B, et eductum C hunc aequationem logicam efficit:
C=A⋅B{displaystyle C=Acdot B} |

Forma |
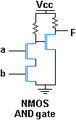
Porta ET, NMOS facta.

Forma alterna |
Si portae ET propriae non adsunt, porta ET ex portis NON-ET aut NON-AUT creare potest, quia illae portae sunt portae universales,[3] quod portas NON-ET aut NON-AUT creare portas omnes alias posse significat. Quamquam portae XAUT portas alias creare possunt, est rarum.
Notae |
↑ Michael H. Tooley, Mike Tooley, David Wyatt (2008) .mw-parser-output .existinglinksgray a,.mw-parser-output .existinglinksgray a:visited{color:gray}.mw-parser-output .existinglinksgray a.new{color:#ba0000}.mw-parser-output .existinglinksgray a.new:visited{color:#a55858}
(Anglice). Aircraft Electrical and Electronic Systems. Butterworth-Heinemann. p. 59
↑ John F. Wakerly (2005). Digital Design Principles and Practices (4a ed.). Prentice Hall. ISBN 0-13-186389-4
↑ M. Morris Mano et Charles R. Kime (2004). Logic and Computer Design Fundamentals (3a ed.). Prentice Hall. p. 73.
Nexus interni
- Algebra booleana (logica)
- Logica NON-AUT
- Logica NON-ET
- Porta AUT
- Porta logica
- Porta NON
- Porta NON-AUT
- Porta NON-ET
- Porta XAUT


